
/cdn.vox-cdn.com/uploads/chorus_asset/file/25424932/Hover_20240429_1714372038159.0__1_.jpeg)




AMD نشر مؤخرًا براءة اختراع لتوزيع الحمل من العرض عبر العديد من شرائح GPU. ينقسم مشهد اللعبة إلى كتل فردية ويوزع على الألواح الخشبية لتحسين استخدام التظليل في الألعاب. يتم استخدام حاوية الرقائق ثنائية المستوى لهذا الغرض.
تنشر AMD براءة اختراع لتطبيق GPU chiplets لتحقيق استخدام أفضل لتقنية shader
تفتح براءة الاختراع الجديدة التي نشرتها AMD مزيدًا من الأفكار حول ما تخطط الشركة للقيام به مع تقنية GPU و CPU من المستوى التالي في السنوات القادمة. في نهاية شهر يونيو ، تم الكشف عن إرسال 54 طلب براءة للنشر. من غير المعروف أي من أكثر من خمسين براءة اختراع منشورة سيتم استخدامها في خطط AMD. توضح التطبيقات التي تمت مناقشتها في براءات الاختراع نهج الشركة على مدار السنوات التالية.
أحد التطبيقات التي لاحظها عضو المجتمع @ ETI1120 على موقع الويب قاعدة الكمبيوتر، رقم براءة الاختراع US20220207827، يناقش بيانات الصورة الهامة على مرحلتين لتمرير الأحمال بكفاءة من العرض من وحدة معالجة الرسومات عبر العديد من الشرائح. طبقت وحدة المعالجة المركزية هذا في البداية على مكتب براءات الاختراع الأمريكي في نهاية العام الماضي.
عندما يتم تحويل بيانات الصورة على وحدة معالجة الرسومات إلى نقطية بالوسائل القياسية ، تقوم وحدة التظليل ، المعروفة أيضًا باسم ALU ، بتنفيذ المهمة المماثلة وتعيين اسم لوني لوحدات البكسل الفردية. في المقابل ، يتم تعيين المضلعات المنسوجة الموجودة في البكسل المحدد في مشهد لعبة معين مباشرة على البكسل. أخيرًا ، ستحافظ المهمة المصاغة على مبادئ غير نمطية وتختلف فقط من خلال الأنسجة الأخرى الموجودة في وحدات بكسل مختلفة. تسمى هذه الطريقة SIMD ، أو التعليمات الفردية – بيانات متعددة.
بالنسبة لمعظم الألعاب الحالية ، فإن التظليل ليس المهمة الوحيدة التي أنجبتها وحدة معالجة الرسومات. ولكن بدلاً من ذلك ، يتم تضمين العديد من عناصر المعالجة اللاحقة بعد التظليل الأولي. الإجراءات التي ستضيفها وحدة معالجة الرسومات ، على سبيل المثال ، ستكون منع التعرجات والتظليل والانسداد في بيئة اللعبة. ومع ذلك ، يحدث تتبع الأشعة جنبًا إلى جنب مع التظليل ، مما يؤدي إلى إنشاء طريقة حساب جديدة.
عندما نتحدث عن وحدة معالجة الرسومات (GPU) التي تتحكم في الرسومات في الألعاب الحالية ، فإن الحمل الذي تم إنشاؤه بواسطة الكمبيوتر يزداد بشكل كبير إلى آلاف وحدات الحوسبة.
في الألعاب على وحدات معالجة الرسومات ، يصل حمل الحوسبة هذا إلى عدة آلاف من وحدات الحوسبة بطريقة مثالية إلى حد ما. هذا يختلف عن المعالجات في أن التطبيقات يجب أن تكون مكتوبة خصيصًا لإضافة المزيد من النوى. ينشئ برنامج جدولة وحدة المعالجة المركزية هذا الإجراء ، ويقسم العمل من وحدة معالجة الرسومات إلى مهام أكثر قابلية للفهم تتم معالجتها بواسطة وحدات الحوسبة ، وتسمى أيضًا binning. يتم تقديم الصورة من اللعبة ثم تقسيمها إلى كتل منفصلة تحتوي على كمية محددة من البكسل. يتم حساب الكتلة بواسطة وحدة فرعية لمعالج الرسومات ، حيث تتم مزامنتها وإنشائها. بعد هذا الإجراء ، يتم تضمين وحدات البكسل التي تنتظر حسابها في كتلة حتى يتم استخدام الوحدة الفرعية لبطاقة الرسومات في النهاية. يتم وضع اعتبارات لقوة الحوسبة للتظليل وعرض النطاق الترددي للذاكرة وأحجام ذاكرة التخزين المؤقت.
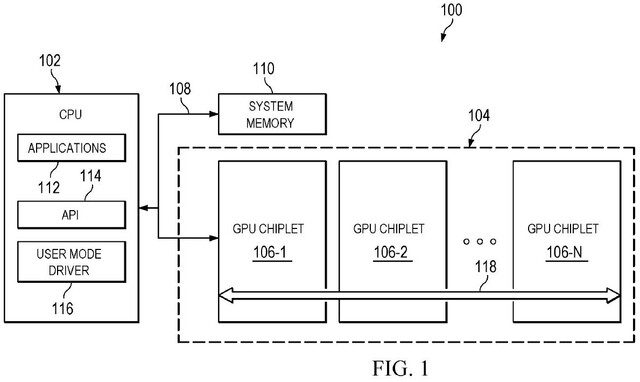
توضح AMD في براءة الاختراع أن التقسيم والانضمام يتطلبان اتصال بيانات شامل وكامل بين جميع عناصر وحدة معالجة الرسومات ، مما يطرح مشكلة. روابط البيانات غير الموجودة على القالب لها مستوى مرتفع من الكمون ، مما يجعل العملية أبطأ.
جعلت وحدات المعالجة المركزية هذا الانتقال إلى chiplets دون عناء نظرًا لقدرتها على إرسال المهمة عبر عدة أنوية ، مما يجعلها في متناول أجهزة chiplets. لا تقدم وحدات معالجة الرسومات نفس المرونة ، مما يجعلها قابلة للمقارنة بالمعالج التمهيدي ثنائي النواة.
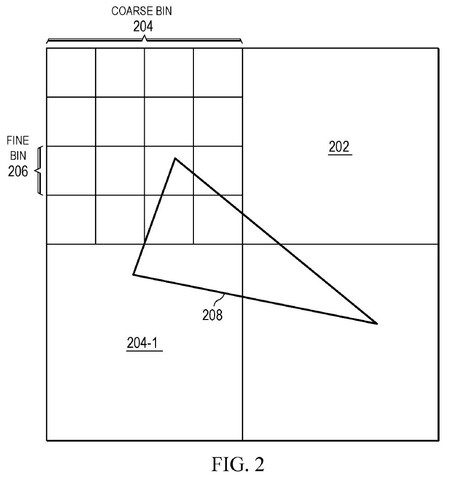
تدرك AMD الحاجة ومحاولات تقديم إجابات لهذه المشكلات عن طريق تغيير خط أنابيب التحويل النقطي وإرسال المهام بين العديد من وحدات معالجة الرسومات ، على غرار وحدات المعالجة المركزية. يتطلب ذلك تقنية binning المتقدمة ، والتي تقدم الشركة “binning binning” ، المعروف أيضًا باسم “binning binning”.


في التجميع الفائق ، تتم معالجة الانقسام إلى مرحلتين منفصلتين بدلاً من المعالجة المباشرة في كتل بكسل تلو الأخرى. تتمثل الخطوة الأولى في حساب المعادلة ، واتخاذ بيئة ثلاثية الأبعاد وإنشاء صورة ثنائية الأبعاد من الأصل. تسمى المرحلة تظليل قمة الرأس وتكتمل قبل التنقيط ، وتكون العملية قليلة للغاية في الشريحة الأولى من وحدة معالجة الرسومات. بمجرد الانتهاء ، يبدأ مشهد اللعبة في التلاشي ، ويتطور إلى صناديق خشنة ومعالجته في شريحة GPU واحدة. بعد ذلك ، يمكن أن تبدأ المهام الروتينية مثل التنقيط والمعالجة اللاحقة.


من غير المعروف متى تعتزم AMD البدء في استخدام هذه العملية الجديدة أو ما إذا كانت ستتم الموافقة عليها. ومع ذلك ، فإنه يعطينا لمحة عن مستقبل معالجة GPU الأكثر كفاءة.
مصادر الأخبار: قاعدة الكمبيوترو براءات اختراع مجانية على الإنترنت

“متحمس لوسائل التواصل الاجتماعي. مهووس بالجعة. متواصل شرير. عاشق لثقافة البوب. عرضة لنوبات اللامبالاة.”
More Stories
مراجعة Fiido Air: خفيفة الوزن لدرجة أنك ستنسى أنها دراجة إلكترونية
سوف يؤدي إحياء iPad Pro من Apple إلى تعطيل نجاح MacBook Pro
أفضل المهارات في Stellar Blade لفتحها في بداية اللعبة 2024